Как надо из наименования, в методах кодировке, относящихся к этой группе, знаки первичного алфавита (к примеру, российского) кодируются комбинациями знаков двоичного алфавита (т.е. 0 и 1), при этом, длина кодов и, соответственно, продолжительность передачи отдельного кода, могут различаться. Продолжительности простых сигналов при всем этом схожи (τ0 = τ1 = τ). Разумеется, для передачи инфы, в среднем приходящейся на символ первичного алфавита, нужно время K(A,2) ∙ τ. Таким образом, задачку оптимизации неравномерного кодировки можно сконструировать последующим образом: выстроить такую схему кодировки, в какой суммарная продолжительность кодов при передаче (либо суммарное число кодов при хранении) данного сообщения была бы меньшей. За счет чего вероятна такая оптимизация? Разумеется, суммарная продолжительность сообщения будет меньше, если применить последующий подход: тем знакам первичного алфавита, которые встречаются в сообщении почаще, присвоить наименьшие по длине коды, а тем, относительная частота которых меньше — коды более длинноватые. Другими словами, коды символов первичного алфавита, возможность возникновения которых в сообщении выше, следует строить из может быть наименьшего числа простых сигналов, а длинноватые коды использовать для символов с малыми вероятностями.
Параллельно должна решаться неувязка различимости кодов. Представим, что на выходе кодера получена последующая последовательность простых сигналов:
00100010000111010101110000110
Каким образом она может быть декодирована? Если б код был равномерным, приемное устройство просто отсчитывало бы данное (фиксированное) число простых сигналов (к примеру, 5, как в коде Бодо) и интерпретировало их в согласовании с кодовой таблицей. При использовании неравномерного кодировки вероятны два подхода к обеспечению различимости кодов.
1-ый состоит в использовании специальной композиции простых сигналов, которая интерпретируется декодером как разделитель символов. 2-ой — в применении префиксных кодов. Разглядим подробнее любой из подходов.
Неравномерный код с разделителем
Условимся, что разделителем отдельных кодов букв будет последовательность 00 (признак конца знака), а разделителем слов-слов — 000 (признак конца слова — пробел). Достаточно явными оказываются последующие правила построения кодов:
- код признака конца знака может быть включен в код буковкы, так как не существует раздельно (т.е. кода всех букв будут заканчиваться 00);
- коды букв не должны содержать 2-ух и поболее нулей попорядку посреди (по другому они будут восприниматься как конец знака);
- код буковки (не считая пробела) всегда должен начинаться с 1;
- разделителю слов (000) всегда предшествует признак конца знака; при всем этом реализуется последовательность 00000 (т.е., если в конце кода встречается композиция …000 либо …0000, они не воспринимаются как разделитель слов); как следует, коды букв могут оканчиваться на 0 либо 00 (до признака конца знака).
В согласовании с перечисленными правилами построим кодовую табл. 3.1 для букв российского алфавита, основываясь на приведенных ранее (табл. 2.1.) вероятностях возникновения отдельных букв.
Сейчас по формуле (А.11) можно отыскать среднюю длину кода К(r,2) для данного метода кодировки:
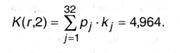
Так как для российского языка, как указывалось в п.2.3., I1(r) = 4,356 бит, избыточность данного кода, согласно (3.5), составляет:
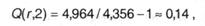
это значит, что при данном методе кодировки будет передаваться примерно на 14% больше инфы, чем содержит начальное сообщение. Подобные вычисления для британского языка дают значение К(е,2) = 4,716, что при I1(e) = 4,036 бит приводят к избыточности кода Q(е,2) = 0,168.
Таблица 3.1.
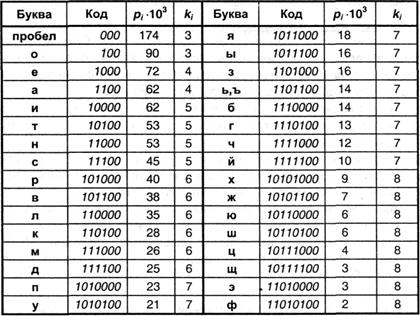
Рассмотрев один из вариантов двоичного неравномерного кодировки, попробуем отыскать ответы на последующие вопросы: может быть ли такое кодирование без использования разделителя символов? Существует ли более действенный (лучший) метод неравномерного двоичного кодировки?
Сущность первой трудности состоит в нахождении такового варианта кодировки сообщения, при котором следующее выделение из него каждого отдельного знака (т.е. декодирование) оказывается конкретным без особых указателей разделения символов. Более ординарными и употребимыми кодами такового типа являются так именуемые префиксные коды, которые удовлетворяют последующему условию (условию Фано):
Неравномерный код может быть совершенно точно декодирован, если никакой из кодов не совпадает с началом (префиксом*) какого-нибудь другого более длинноватого кода.
* В языковедении термин «префикс» значит «приставка».
К примеру, если имеется код 110, то уже не могут употребляться коды 1, 11, 1101, 110101 и пр. Если условие Фано производится, то при прочтении (расшифровке) закодированного сообщения методом сравнения с таблицей кодов всегда можно точно указать, где завершается один код и начинается другой.
