Структура информационного массива определяется один раз на шаге его сотворения и в процессе эксплуатации уже не меняется. В языках программирования это достигается описанием структуры в блоке описаний программки; в СУБД — установлением списка и последовательности полей записи на исходном шаге сотворения базы данных. Всякое изменение структуры (к примеру, введение дополнительного поля записи либо удаление имеющегося) эквивалентно созданию новейшей структуры. Что все-таки касается количества записей в структурированном информационном массиве, то при представлении его в ОЗУ компьютера вероятны две ситуации: или под него выделяется область ОЗУ фиксированного размера, или размер области по мере надобности может изменяться.
В первом варианте сначала работы программки происходит резервирование областей ОЗУ для хранения информационных массивов. С этой целью в тексте программки указывается, какого типа и размера информационные массивы будут в предстоящем применены. В процессе выполнения программки могут изменяться значения частей информационного массива, но не его размер. По этой причине в случае, если размер (число частей) массива не известен заблаговременно (к примеру, количество учеников в классе), приходится производить лишнее резервирование, что, непременно, приводит к нерациональному использованию памяти компьютера. Конкретно таким макаром происходит резервирование памяти при описании массивов и других структурных данных в языке PASCAL. Отсутствие способностей динамического описания массивов (т.е. введение новых массивов либо изменение размеров имеющихся в процессе выполнения программки) считается одним из существенных недочетов языка программирования.
Информационные массивы, допускающие изменение размера (но не структуры!) именуются динамическими. В данном случае данные могут иметь последовательное либо связное представление в ОЗУ.
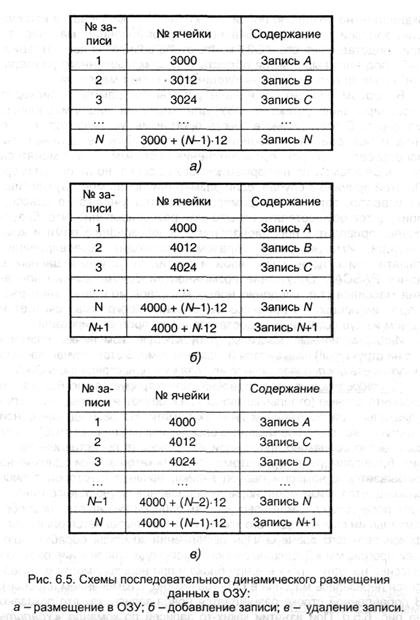
Последовательное представление иллюстрируется рис. 6.5. В этом варианте данные (отдельные записи) располагаются в примыкающих поочередно расположенных ячейках памяти. На размещение одной записи может потребоваться несколько ячеек (машинных слов), но их количество идентично для каждой из записей (в представленном на рис. 6.5,а примере — 12), потому идентификатор записи совершенно точно связывается с номером первой ячейки, начиная с которой запись располагается. Физический порядок следования стопроцентно соответствует логическому. Такая совокупа записей именуется поочередным перечнем. Для его хранения в ОЗУ выделяется блок ячеек фиксированного размера. При выполнении команды обрабатывающей программки «Добавить запись» происходит повышение размера массива на одну строчку в конце блока и по мере надобности делается перезапись массива в ОЗУ (может быть, с конфигурацией адресов). В добавленной строке располагается новенькая запись, как это показано на рис. 6.5,б. При изъятии каких-либо записей по команде «Удалить запись» соответственная строчка очищается и после перезаписи заполняется содержимым последующих ячеек (рис. 6.5,в).
Связное представление данных основано на том, что в записи дописывается дополнительное поле, в каком располагается указатель адреса, т.е. ссылка на то место в ОЗУ, где размещается последующая запись. При всем этом физический порядок размещения записей не соответствует логическому — записи размещаются в всех свободных ячейках ОЗУ, при этом, не непременно по порядку. Такие структуры именуются связными перечнями. Их удобство состоит в гибкости структуры — без перезаписи других частей можно просто добавлять новые либо исключать имеющиеся — для этого довольно только поменять состояние поля указателя адреса, что иллюстрируется рис. 6.6.
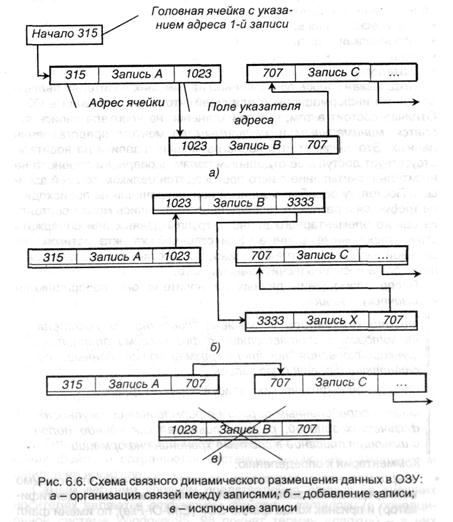
Недочет описанного метода представления информационного массива в ОЗУ заключается в том, что в нем нереально впрямую обратиться к подходящей записи — поиск ее осуществляется по цепочке переходов, непременно, увеличивая время доступа к данным.
